A Deeper Look at ROC-AUC
November 15, 2020 | 4 min read
You’ve probably heard about the ROC-AUC, or simply AUC, which is defined as the area under the receiver operating characteristic (ROC) curve. This is indicated by the blue area in the figure below and is used to evaluate the performance of classification models.
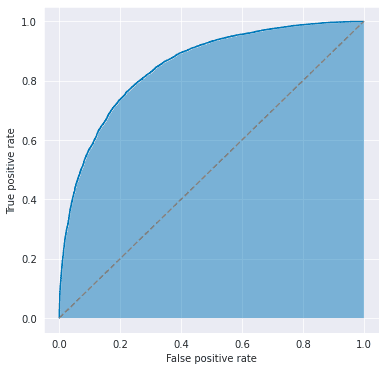
The ROC curve is obtained by plotting the pairs of false positive and true positive rates as changing the threshold for binary classification, where
Therefore, this metric does not depend on the choice of the threshold and is useful when you want to consider the TPR-FPR trade-offs. It takes a value of 0.5 (= area under the dashed line) for a random binary classification model and 1.0 (= area under the line ) for a perfectly correct model.
Relationship with Gini Coefficient
ROC-AUC has a linear relationship with the Gini coefficient, which is defined as the ratio of areas in the figure below.
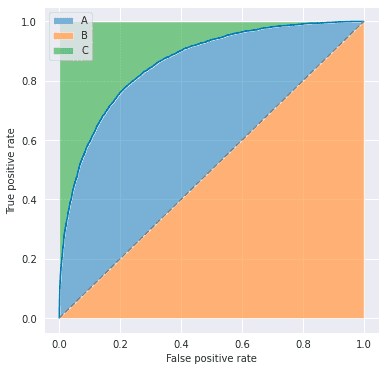
That is,
Looking at AUC from a Different Perspective
Let’s consider another way of looking at ROC-AUC with a fun example: an emoji classifier. This classifier can predict whether the given emoji is happy or not, but its prediction is not perfect. Its outputs look like below:
| Index | Face | Label | Prediction |
|---|---|---|---|
| 0 | 😆 | 1 | 0.9 |
| 1 | 😁 | 1 | 0.8 |
| 2 | 😄 | 1 | 0.7 |
| 3 | 😕 | 0 | 0.6 |
| 4 | 😃 | 1 | 0.5 |
| 5 | 🙁 | 0 | 0.4 |
| 6 | 😀 | 1 | 0.3 |
| 7 | 😣 | 0 | 0.2 |
| 8 | 😖 | 0 | 0.1 |
| 9 | 😫 | 0 | 0.0 |
Note that the classifier says the happy emoji ”😀 ” is 30% happy and the sad emoji ”🙁” is 60% happy. Now, what is the ROC-AUC of this model?
Well, by increasing the threshold from 0.0 to 0.9, you’ll get a ROC curve that looks like below. The threshold values are indicated along the line, so you’ll see that as you increase the threshold, both FPR and TPR go down.
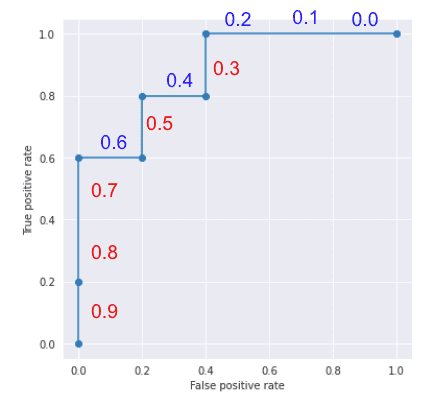
By counting the number of squares enclosed in the grid, we find that the ROC-AUC is 0.88 (one square is equivalent to 0.04).
The operation above is equivalent to, for each positive sample, counting the number of negative samples with a smaller score. A happy emoji ”😆” is predicted to be happier than ”😕 🙁 😣 😖 😫” so its count is 5. Another happy emoji ”😀” is predicted happier than ”😣 😖 😫 ” so its count is 3. And so on.
| Index | Face | Predicted Happier than… | Count |
|---|---|---|---|
| 0 | 😆 | 😕 🙁 😣 😖 😫 | 5 |
| 1 | 😁 | 😕 🙁 😣 😖 😫 | 5 |
| 2 | 😄 | 😕 🙁 😣 😖 😫 | 5 |
| 4 | 😃 | 🙁 😣 😖 😫 | 4 |
| 6 | 😀 | 😣 😖 😫 | 3 |
The total count is 22, meaning that ROC-AUC is . So, ROC-AUC can be computed by the following steps.
- Create a matrix like the figure below, where positive samples are placed on the vertical axis and negative samples on the horizontal axis, both in the descending order of the predicted values from the origin
- For each pair of positive and negative samples, check if the score of the positive sample is larger than the one of the negative sample.
- ROC-AUC is the ratio of the checked pairs to the total pairs.
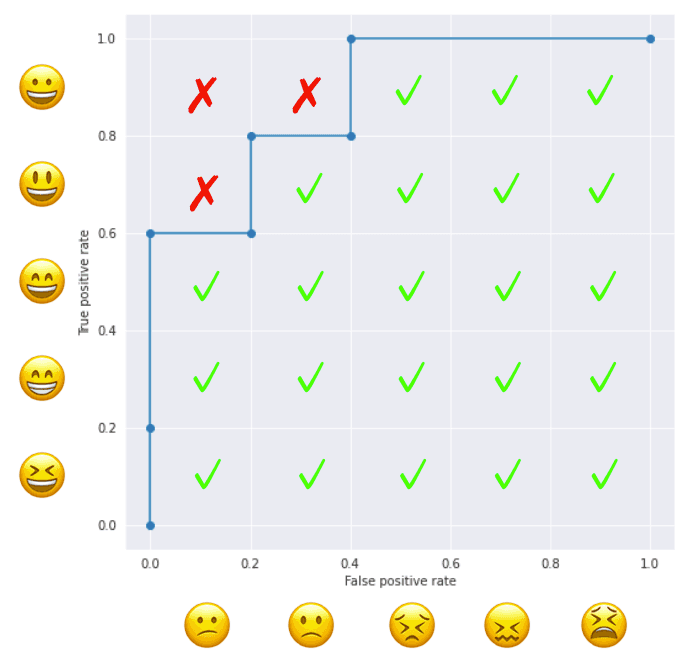
Now we have the following formula:
where is the set of positive samples and is the set of negative samples.
Relationship with Mann–Whitney U Test
This counting operation can also be seen in the Mann-Whitney U test (a.k.a. Mann–Whitney–Wilcoxon (MWW) test and Wilcoxon rank-sum test). MWW test is a nonparametric test of the null hypothesis that two populations are the same, particularly for the case one population tends to have larger values than the other.
Given i.i.d samples from and i.i.d samples from , MWW test considers the following statistic called Mann-Whitney U statistic.
counts the number of that is smaller than , and the outer takes the sum over all the samples from . If the U statistic is sufficiently large, the MWW test rejects the null hypothesis.
References
[1] Mann–Whitney U test - Wikipedia
[2] Mann-Whitney Hypothesis Test | Six Sigma Study Guide
[3] 門脇大輔,阪田隆司,保坂桂佑,平松雄司. ”Kaggleで勝つデータ分析の技術”. 技術評論社. 2020. pp.75-77.
![[object Object]](/static/2d0f4e01d6e61412b3e92139e5695299/d8057/profile-pic.webp)
Written by Shion Honda. If you like this, please share!



























